How Multi-Agent Systems Work and Why One AI Agent Is Never Enough
A multi-agent system is a network of AI agents that each handle specific tasks and communicate to achieve a shared goal. Instead of relying on one model to do everything, multiple specialized agents divide the work, check each other’s output, and coordinate in real time. This makes them far more capable than any single agent working alone.
Picture a situation where your AI tool needs to search the web, write a report, run a piece of code, cross-reference a database, and then format the output for a specific audience, all as part of a single request. You ask your AI assistant to handle it. Halfway through, the model loses track of what it was doing. Output quality drops. The final result is inconsistent, incomplete, or flat-out wrong.
This is not a hypothetical. It is what happens regularly when people push a single AI model past its natural limits.
The solution is not a bigger, more powerful model. The solution, increasingly, is a multi-agent system. This piece walks through how these systems actually work, what they are made of, why they outperform single-agent setups on complex tasks, and what the real challenges look like when you try to build one.
What Is a Multi-Agent System, Really?
At its core, a multi-agent system is a group of AI agents that operate together, each taking responsibility for a specific part of a larger job. The agents communicate with one another, pass results back and forth, and collectively produce an output that none of them could have managed alone.
The analogy that makes the most sense here is a professional services firm. A law firm does not ask one junior associate to handle client intake, draft contracts, appear in court, manage billing, and file regulatory documents simultaneously. It assigns each function to the person or team best equipped for it. A multi-agent AI system works on the same logic. Each agent has a lane, and the lanes are defined carefully so that the handoffs between them are clean and reliable.
A typical setup might include an agent that retrieves information from the web, one that synthesizes that information into structured notes, another that transforms those notes into polished content, and a final agent that reviews everything for accuracy before delivery. The individual agents do not need to know what everyone else is doing. They need to execute their piece of the workflow and pass the result forward.
This is exactly the insight behind recent academic research on the topic. A peer-reviewed study published in the journal Electronic Markets found that multi-agent AI systems differ fundamentally from traditional automation pipelines because agent interactions emerge dynamically in response to context rather than following a fixed, predetermined script. That capacity for dynamic response is what gives these systems their edge on messy, real-world problems where conditions shift and no two inputs are exactly alike.
Breaking Down the Architecture
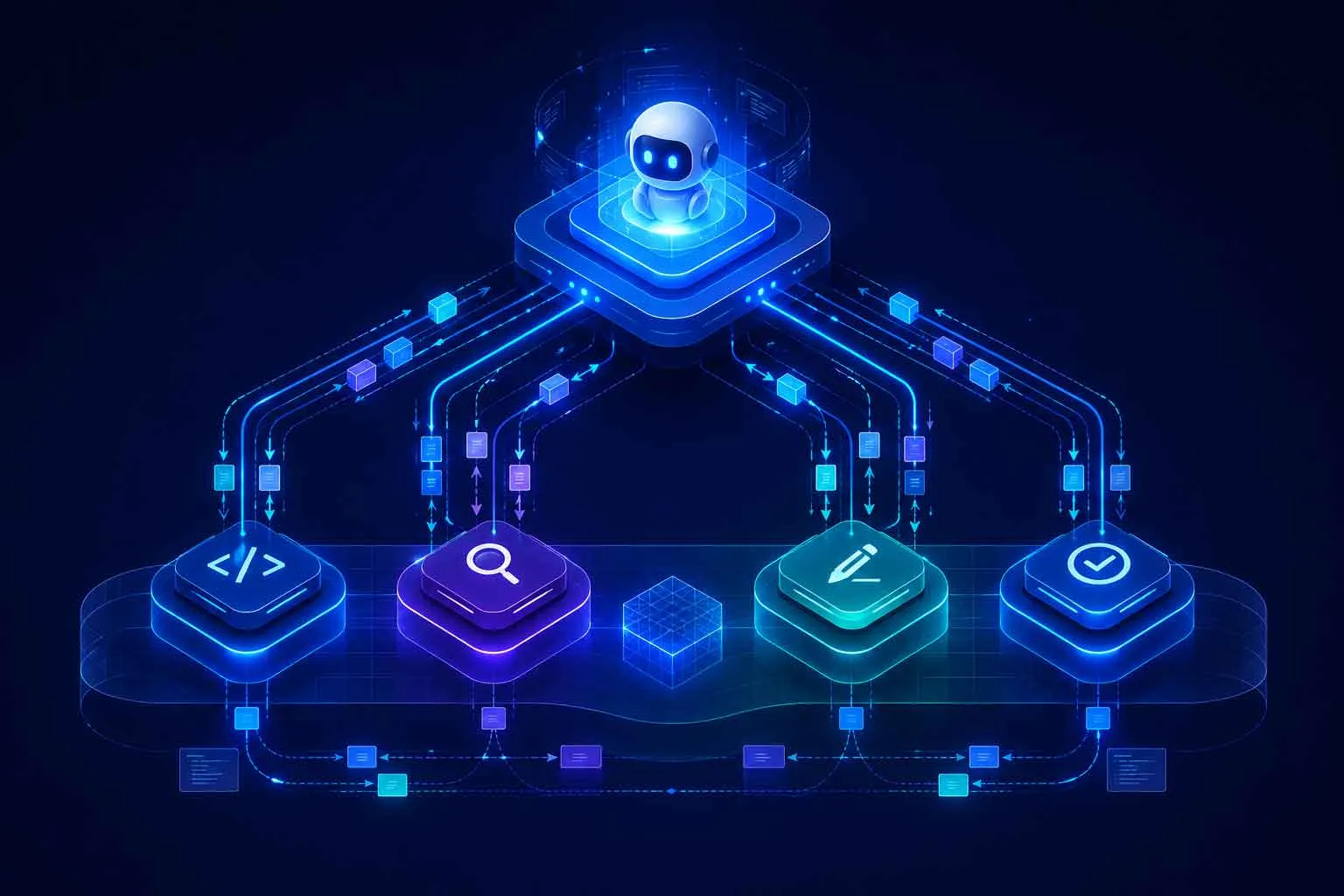
If you want to understand how multi-agent systems work in practice, you need to understand what they are built from. Each component plays a distinct role.
The Orchestrator
The orchestrator is the coordinator of the entire system. It receives the original request, decides how to break it into smaller tasks, determines which agents are best suited to handle each one, and sequences the work so that each step feeds properly into the next.
Importantly, the orchestrator does not do the substantive work itself. It is a planner and a router. Think of it as the project lead who manages a team without personally handling every deliverable. Good orchestration is what separates a multi-agent system that feels seamless from one that feels like a series of disconnected steps.
Specialized Sub-Agents
These are the agents that actually get things done. Each sub-agent is optimized for a particular type of task. A coding agent knows how to read, write, debug, and test code. A retrieval agent knows how to query databases and APIs efficiently. A writing agent knows how to structure prose for clarity and flow. A review agent knows how to catch inconsistencies and flag errors.
The specificity is deliberate. A general-purpose model spread across too many task types tends to be average at most of them. Specialized agents, tuned for their specific domains, tend to be considerably better at their designated functions. When you chain several specialized agents together, you get compound performance that a single generalist model cannot match.
Memory and Context Management
This is one of the less glamorous but most important aspects of multi-agent system design. Every AI model operates within a context window, which is a fixed amount of text it can process and hold in working memory at any given time. For simple, short interactions this is rarely a problem. For complex, long-running workflows, it becomes a serious constraint.
Multi-agent systems handle this by distributing memory across the system. Some agents maintain short-term memory within a session, passing relevant context as structured messages when they hand off to the next agent. Other systems use persistent memory stores, including vector databases and document stores, that any agent can query at any point in the workflow. The goal is to ensure that no single agent is ever overwhelmed by context it cannot hold, while also ensuring that critical information is never silently dropped.
Communication Protocols
The agents in a multi-agent system talk to each other through structured communication channels. This might involve formatted JSON messages, function calls, shared document workspaces, or purpose-built agent communication protocols. The structure matters. Unstructured communication between agents creates ambiguity, and ambiguity causes errors. Well-designed communication contracts, where every agent knows exactly what format to expect from the one upstream and exactly what format to deliver to the one downstream, are a significant factor in whether a system performs reliably at scale.
The Case Against the Single-Agent Approach
There is a version of this conversation where someone argues that if models just keep getting more capable, multi-agent systems will eventually be unnecessary. That argument misunderstands the nature of the problem.
The limitations of a single-agent approach are not primarily about raw intelligence. They are structural. Here is what that looks like in practice.
Context Windows Have Hard Limits
Every language model has a ceiling on how much information it can actively process. As a task grows in length and complexity, the model begins to lose track of earlier details. It contradicts itself, repeats steps it has already completed, or forgets constraints that were specified at the beginning of the conversation. Expanding the context window helps, but it does not eliminate the problem entirely, and it increases the computational cost of every single call. Multi-agent systems sidestep this by distributing context across multiple agents, each of which only needs to hold the portion of the task relevant to its specific function.
General Models Are Spread Thin
A model built to handle everything from creative writing to financial analysis to code debugging is by definition a generalist. Generalists are useful, but they are not optimal for specialized work. When precision matters, a dedicated agent trained or prompted specifically for that domain will consistently outperform a generalist model attempting the same task as one of a hundred it might encounter.
Errors Snowball Without Checkpoints
In a single-agent workflow, a mistake made early in the process propagates through every subsequent step. There is no natural mechanism for catching and correcting it before it compounds. Multi-agent systems introduce review and validation at the handoff points between agents. One agent produces output, another evaluates it before passing it downstream. That built-in quality control prevents small errors from becoming large ones.
Some Work Is Inherently Parallel
There are tasks where sequential processing is simply inefficient because different parts of the work do not depend on each other. Writing five independent sections of a report, for example, does not require completing section one before starting section two. A multi-agent system can assign those sections to different agents running simultaneously, completing the work in a fraction of the time a single agent working sequentially would need.
Tool Access Becomes Unwieldy
Modern AI workflows often require access to many different tools: search engines, code execution environments, databases, APIs, content management systems. Giving a single agent access to all of these creates a bloated, hard-to-manage setup where the model has to navigate an enormous toolkit on every request. Multi-agent systems allow you to give each agent access only to the tools relevant to its function, keeping things clean, auditable, and far easier to debug when something goes wrong.
How Agents Actually Communicate
The communication layer of a multi-agent system deserves its own discussion because it is often where well-designed systems separate themselves from poorly designed ones.
Message Passing
The foundational communication method is message passing. One agent completes its work, packages the output in a structured format, and sends it to the next agent in the workflow along with any relevant context. The receiving agent reads the message, uses it to inform its own work, and passes its output along in turn. When this is done well, the chain of handoffs feels invisible. When it is done poorly, the cracks show up in inconsistent outputs and difficult-to-trace errors.
Tool Invocation
Many agents communicate indirectly by calling tools on behalf of the workflow. A research agent might call a web search API. A data agent might query a SQL database. A notification agent might call an email or messaging API. In more advanced setups, one agent can call another agent as if it were a tool, which allows for flexible, dynamic delegation that adjusts based on what the workflow needs at any given moment.
Shared Workspaces
Some multi-agent systems use a shared workspace model, where all agents have read and write access to a common document or data structure. This approach works particularly well for iterative tasks like drafting a long document or building a codebase, where multiple agents need to see each other’s contributions and respond to them in near real time.
Review and Feedback Loops
The most robust multi-agent systems include deliberate feedback mechanisms. Rather than passing outputs forward unconditionally, an evaluator agent assesses the quality of each output against defined criteria. If the output does not meet the bar, it is sent back for revision. This mirrors how well-functioning human teams operate, and it significantly improves the reliability of the final output.
Where Multi-Agent Systems Are Being Used Today
These systems are not experimental. They are actively deployed across a wide range of industries, handling tasks that would have required significant human effort not long ago.
Software Engineering Pipelines
Multi-agent systems fit naturally into software development workflows. An analysis agent examines incoming bug reports and maps them to likely areas of the codebase. A coding agent writes a proposed fix. A testing agent runs the fix through an automated test suite and reports the results. A documentation agent updates the relevant documentation to reflect the change. The entire cycle can run with minimal human involvement, and because each agent is focused on a specific function, the quality of each step tends to be high.
This kind of AI-powered development infrastructure is increasingly what enterprise software teams are moving toward. For organizations looking to implement these pipelines properly, Bantech’s Enterprise Software Development services are built specifically to architect and deliver intelligent, production-ready systems at scale, taking the guesswork out of translating this architecture into something your business can actually use.
Research and Knowledge Work
Long-form research is another natural fit. A retrieval agent finds and pulls relevant sources from the web or from internal document stores. A synthesis agent reads through the retrieved material and identifies the key findings. A writing agent structures those findings into a coherent report. A verification agent cross-checks claims against the source material. The result is a level of research quality and speed that a single model working alone cannot consistently match.
Customer Operations
Customer-facing workflows that span multiple backend systems benefit significantly from multi-agent coordination. An intent agent interprets what the customer is asking. A data agent queries the relevant order, account, or inventory system. A resolution agent determines the appropriate response. A communication agent composes and delivers that response in the right tone and format. Each step is cleaner and more accurate because each agent is doing one thing rather than everything.
Clinical and Healthcare Applications
Healthcare environments are beginning to apply multi-agent architectures to clinical workflows, routing patient-related questions to agents with domain expertise in specific areas such as pharmacology, diagnostics, or administrative compliance. Each agent brings focused knowledge to its part of the process, reducing the risk of a general model making a confident but incorrect inference in a domain where accuracy is critical.
Financial Analysis and Reporting
In financial services, multi-agent systems are being used to pull market data, cross-reference it against portfolio positions, apply regulatory filters, and generate compliant reports, all within a single coordinated workflow. The speed and precision advantages are significant for an industry where both timeliness and accuracy carry real consequences.
The Challenges You Should Know About Before You Build
Adopting a multi-agent architecture is not without its complications. The benefits are real, but so are the difficulties.
Coordination Complexity
Every agent you add to a system creates more points of coordination, and more points of coordination means more potential failure modes. A misrouted task, an unexpected output format from one agent, or a subtle ambiguity in the instructions passed between agents can break a pipeline in ways that are genuinely difficult to diagnose. The orchestration logic has to be precise, and the communication contracts between agents have to be enforced consistently.
Latency Compounds
Each agent call adds time to the workflow. A pipeline with eight sequential steps, where each step involves a model call that takes a few seconds, starts to feel slow compared to a single direct model call. Parallelism can reduce this, but it requires careful analysis of which steps can genuinely run concurrently and which depend on prior results. Getting that analysis wrong either leaves performance on the table or causes agents to operate on incomplete information.
Observability Is Non-Trivial
In a single-agent setup, when something goes wrong, you look at the conversation. In a multi-agent system, the failure might have occurred at any point in a complex graph of agent interactions. You need comprehensive logging of every message passed, every tool call made, and every output generated at every step of the pipeline. Building and maintaining that observability infrastructure adds meaningful overhead to the project.
The Cost of Running Multiple Models
Running six or eight model calls to complete a single user request costs more compute than running one. At low volumes this is manageable. At scale it can become a significant line item. Thoughtful system design means matching the right model size to each task, using lighter, cheaper models for simpler steps and reserving more capable models for the steps that genuinely require them.
Maintaining Trust and Human Oversight
As agents take on more autonomous actions, especially actions that interact with real-world systems like sending emails, executing database writes, or placing orders, the stakes of getting it wrong increase. You need clear policies around what each agent is authorized to do, how irreversible actions are flagged before execution, and how humans stay meaningfully in the loop for decisions that matter. These are not just technical concerns. They are governance concerns, and treating them as an afterthought is how real problems get created.
Design Principles That Separate Good Systems from Great Ones
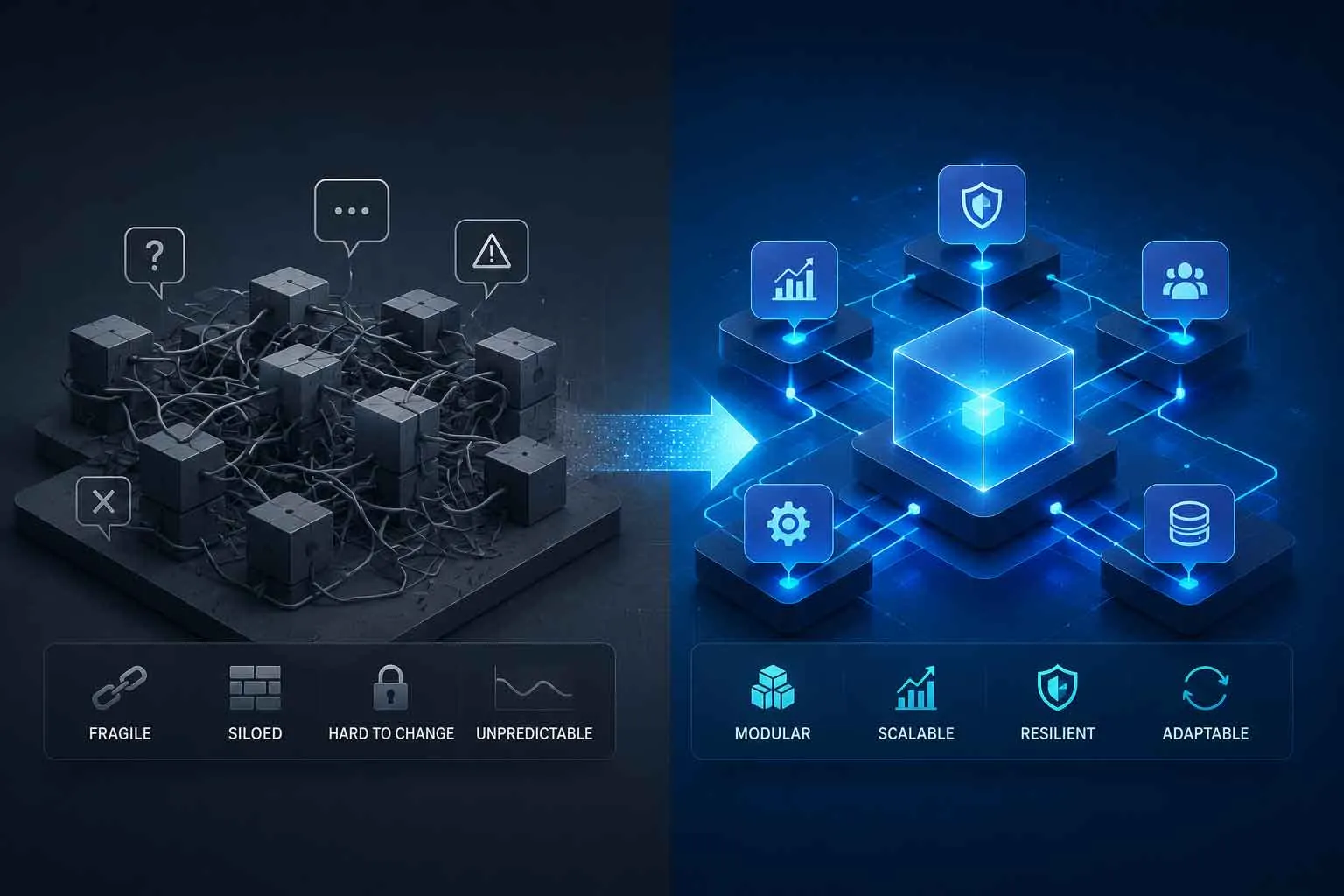
After working through the architecture, the applications, and the challenges, a few core principles consistently show up in multi-agent systems that perform well over time.
Keep Agent Scope Narrow
The agents that work best are the ones with tightly defined responsibilities. The temptation when designing a multi-agent system is to build agents that are capable of handling a wide range of scenarios. In practice, broad-scope agents become harder to test, harder to debug, and less reliable. Every time you find yourself adding capabilities to an agent that already works, ask whether a new, dedicated agent would serve the purpose better.
Treat Communication as a Contract
The interface between agents should be treated like a software contract: explicit, versioned, and enforced. Every agent should document exactly what it expects as input and exactly what it guarantees as output. When those contracts are informal or loosely defined, the system works fine during development and becomes brittle in production. Investing in clear communication specifications early pays off many times over as the system grows.
Build for Reviewability
If a human cannot look at the output of any given agent and understand why it produced what it produced, the system will be very hard to improve. Design agents to produce outputs that are explainable, and design the orchestrator to log decisions in a way that can be traced back through the chain of reasoning. This is partly an observability concern and partly a design philosophy: if the system cannot explain itself, it will be very difficult to know when it is failing in subtle ways.
Start Small and Prove Each Layer
The right way to build a multi-agent system is not to design the full architecture and then implement it all at once. Start with the simplest version that addresses the core problem. Add agents one at a time, validating that each new addition improves the system before moving forward. A two-agent system that works reliably is more valuable than a ten-agent system with mysterious failure modes buried somewhere in the middle.
Preserve Meaningful Human Oversight
Automation is the goal, but removing humans from the loop entirely on high-stakes decisions is a risk that is rarely worth taking. Design your system so that consequential decisions, ones that are expensive to reverse or that carry significant downstream implications, are surfaced for human review before execution. The goal is not to slow things down. The goal is to catch the errors that matter before they become problems.
What the Future of Multi-Agent AI Looks Like
The pace of development in this space has been remarkable. What began as an academic concept has moved into production systems faster than most technology transitions of comparable complexity. Frameworks for building multi-agent systems have matured, the underlying models have gotten better at following structured instructions, and real-world deployments have generated the kind of practical knowledge that makes future systems more reliable.
The next meaningful shift will likely be toward greater adaptability. Most current multi-agent systems operate on relatively fixed workflow graphs: the orchestrator follows a defined sequence, and the agents execute predictable steps. The emerging direction is toward systems that can reason about their own workflow and restructure it on the fly when the task turns out to be different from what was anticipated. An agent that discovers mid-workflow that it needs a capability it was not originally given, and can dynamically recruit or invoke a new agent to fill that gap, represents a meaningful step forward.
Long-term memory and cross-session learning are also active areas of development. Agents that retain knowledge from past workflows and use it to inform future decisions, without requiring a full model retraining, could dramatically improve the efficiency and personalization of these systems over time.
The safety and governance dimension will only become more important as these systems take on more consequential roles. Organizations that are serious about deploying multi-agent AI responsibly are already thinking carefully about authorization frameworks, audit trails, and the conditions under which autonomous action is appropriate versus when human judgment is required. Getting those frameworks right now, while the technology is still relatively new, is far easier than retrofitting them onto mature systems that were built without them.
For organizations ready to move beyond experimentation and deploy multi-agent AI in production, having the right technical partner matters enormously. Bantech’s AI-driven solutions are designed for exactly this stage of the journey, combining deep technical expertise with a practical understanding of what it takes to deploy intelligent systems that are reliable, scalable, and built to last.
Conclusion
The question of whether one AI agent is ever enough has a fairly clear answer: for a narrow, well-defined task with limited context requirements, one agent can work well. For anything more ambitious, the architecture starts to matter, and single-agent setups carry structural limitations that no amount of prompt engineering fully resolves.
Multi-agent systems address those limitations directly. They distribute context so no one model carries too much. They apply specialization so each task goes to the agent best equipped to handle it. They introduce checkpoints so errors are caught before they propagate. They enable parallelism so work that does not need to be sequential does not have to be.
The trade-off is real: these systems are more complex to design, more demanding to build, and require more deliberate thinking about communication, coordination, and oversight. But the performance ceiling they unlock is fundamentally different from what a single model can offer.
Understanding that gap, and knowing how to close it with the right architecture, is one of the more valuable pieces of technical knowledge you can carry into the current era of AI development. The organizations building serious AI capabilities are largely building them as multi-agent systems. That is not a coincidence. It is the logical conclusion of thinking carefully about what these systems actually need to do.